

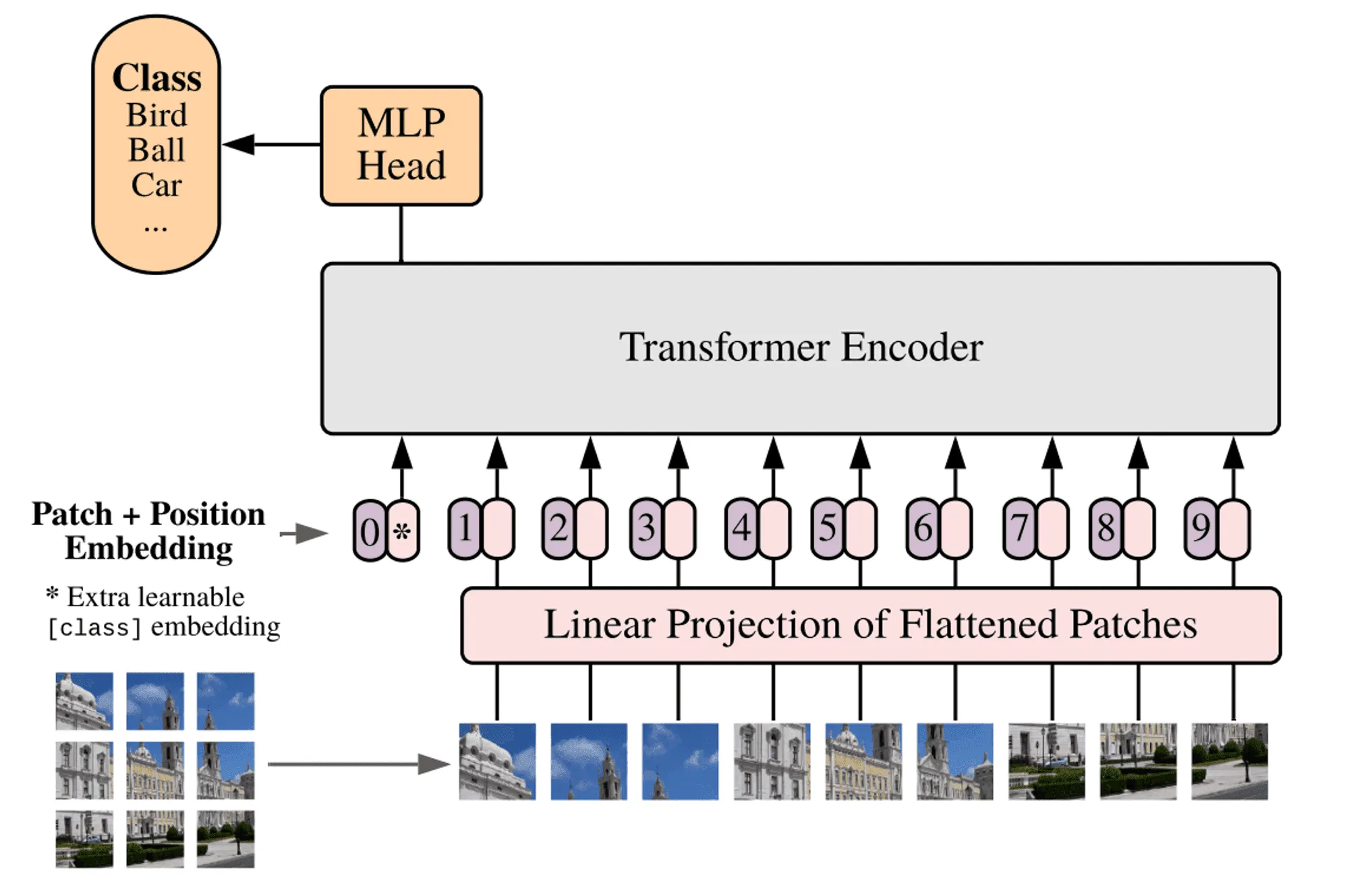
Introduction
The Vision Transformers (ViT) Market is rapidly emerging as transformer-based architectures revolutionize computer vision across industries. Vision Transformers apply transformer neural network models—originally built for natural language processing—to image classification, object detection, segmentation, and visual recognition tasks. ViTs break down images into patches and process them in parallel, enabling superior accuracy, scalability, and performance compared to traditional convolutional neural networks (CNNs). As deep learning applications expand across healthcare, automotive, retail, defense, robotics, and industrial automation, Vision Transformers are becoming a key technology for next-generation AI-powered visual analytics. The growing demand for high-precision image interpretation, edge AI processing, and real-time decision-making is accelerating ViT adoption. With advancements in pretrained models, transfer learning, and multimodal AI, the Vision Transformers market is poised for strong growth.
Market Drivers
Rising use of AI-driven computer vision solutions across sectors such as autonomous vehicles, medical imaging, robotics, and surveillance fuels ViT adoption. Vision Transformers deliver higher accuracy in image analysis and outperform CNNs in large-scale datasets, making them ideal for complex visual tasks. Growth in edge computing and AI hardware accelerators supports efficient ViT deployment for real-time inference. Increased availability of large datasets and self-supervised pretraining models enables faster model training and deployment. Demand for automated quality inspection, facial recognition, and visual analytics in manufacturing, retail, and security drives market growth. Investments by tech giants and startups in ViT-based research, AI labs, and GPU/TPU infrastructure further boost market expansion. The rise of multimodal AI—combining text, image, and sensor inputs—also supports advanced ViT applications.
Market Challenges
High computational requirements for training and deploying ViT models pose a barrier for small enterprises. Vision Transformers demand powerful GPUs, TPUs, and large datasets, increasing infrastructure costs. Data labeling complexity and the need for high-quality training datasets slow adoption in industries with limited AI maturity. Power consumption is higher compared to lightweight CNN models, impacting edge deployment in resource-constrained environments. Lack of standardized benchmarks for certain industry-specific applications creates integration challenges. Skilled AI talent shortage and limited expertise in transformer-based computer vision frameworks hinder adoption in developing regions. Concerns around data privacy, ethics, and bias in AI training models also require careful governance and compliance.
Market Opportunities
Advancements in optimized ViT architectures—such as Swin Transformers, DeiT, MobileViT, and EfficientFormer—create opportunities for cost-efficient and faster model performance. Vision Transformer integration in edge AI devices, surveillance cameras, drones, and smart sensors opens new growth avenues. In healthcare, ViTs can enhance radiology, pathology, and disease detection through high-accuracy image interpretation. Automotive and ADAS systems can leverage ViTs for 3D perception, driver monitoring, and autonomous navigation. Growth in AR/VR, robotics, and multimodal AI creates demand for ViTs capable of real-world contextual understanding. Cloud and AI-as-a-service platforms enable SMEs to access pre-trained ViT models without heavy infrastructure investment. Defense and aerospace applications for surveillance, target tracking, and satellite imaging present high-value opportunities.
Regional Insights
North America leads the Vision Transformers Market driven by strong AI research ecosystems, tech innovation, and adoption across healthcare, automotive, and defense sectors. The U.S. dominates with major AI companies, cloud providers, and R&D investments. Europe follows with focus on AI ethics, industrial automation, and smart manufacturing, with strong adoption in Germany, France, and the UK. Asia-Pacific is the fastest-growing region, led by China, Japan, South Korea, and India, supported by AI investments, semiconductor R&D, and adoption in robotics and smart cities. China remains a key player in vision AI across surveillance, e-commerce, and autonomous mobility. The Middle East is emerging with adoption in smart city projects, security, and retail automation. Latin America and Africa are gradually adopting ViT solutions as AI adoption expands.
Future Outlook
The Vision Transformers Market will evolve with smaller, faster, and more efficient models tailored for edge and embedded systems. Hybrid models integrating CNNs and transformers will optimize speed and accuracy. Multimodal Vision Transformers combining vision, language, audio, and sensor data will drive next-gen AI applications. On-device ViT inference powered by AI chips, neuromorphic computing, and quantum AI research will further accelerate innovation. Self-supervised and few-shot learning will reduce dependency on large labeled datasets. As industries adopt autonomous systems, Vision Transformers will become core components of real-time perception and AI decision systems. Over the next decade, ViTs will reshape computer vision as enterprises shift from rule-based and CNN systems to transformer-centric, context-aware AI.
Conclusion
The Vision Transformers Market is expanding rapidly as transformer-based models redefine computer vision performance and capability. While high compute needs, skill gaps, and data challenges exist, advancements in optimized architectures, edge ViT deployment, and AI democratization are accelerating adoption across industries. As AI moves toward more contextual, predictive, and multimodal intelligence, Vision Transformers will play a foundational role in next-generation visual analytics and automation. Organizations investing in scalable ViT solutions, pretrained models, and edge AI integration will lead the future of intelligent visual systems.